

以前Twitter APIの利用申請をしたところ、
rejectされてしまったので(今のところ同一アカウントでは再申請不可)、
今回は、データダウンロードをして、DMの内容を文書クラスタリングしてみることにした。
DMのデータダウンロード
まずは、設定→アカウント→データのアーカイブをダウンロード
からデータのアーカイブをリクエストする。
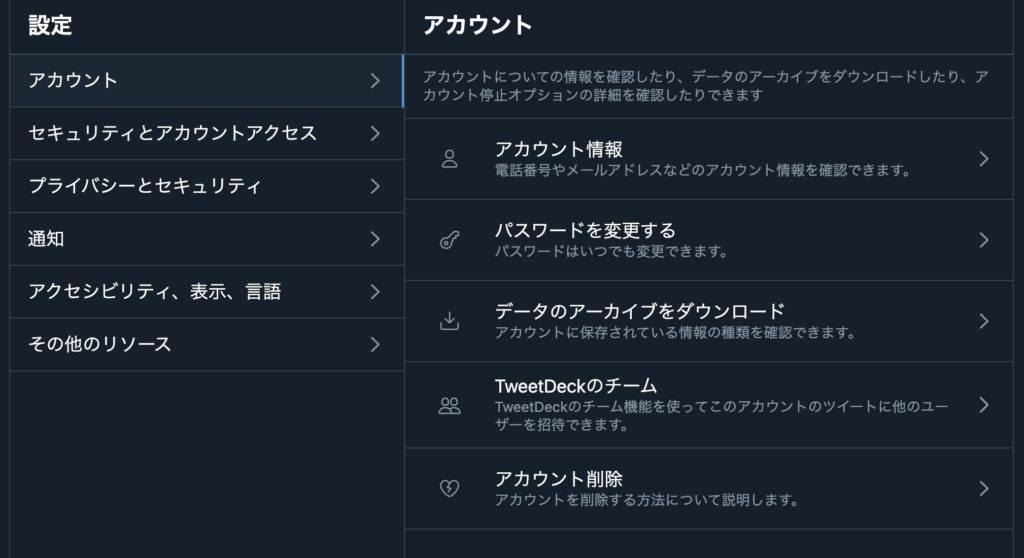
するとパスワードの入力を求められるので、パスワードを入力する。
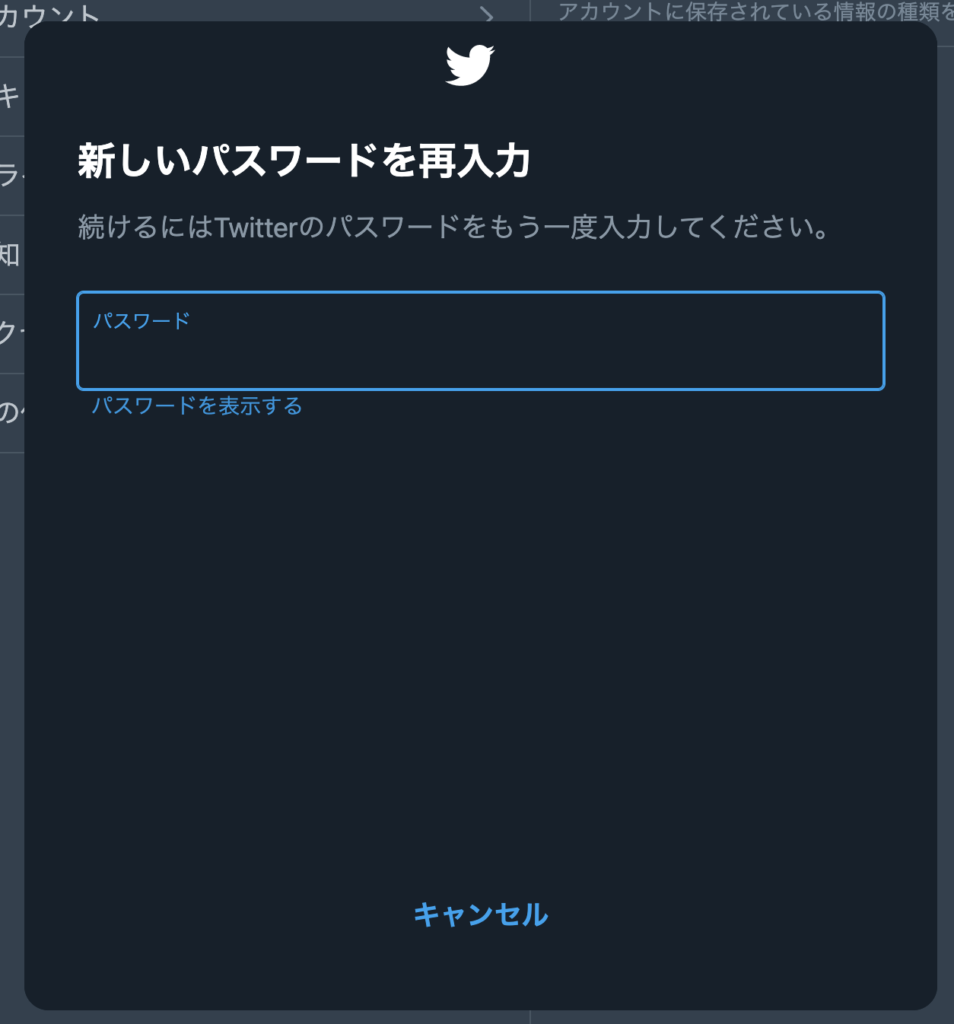
入力すると携帯のSMSに認証パスワードが届くので、それを入力する。
すると以下の状態になるので、アーカイブをリクエストをクリックする。
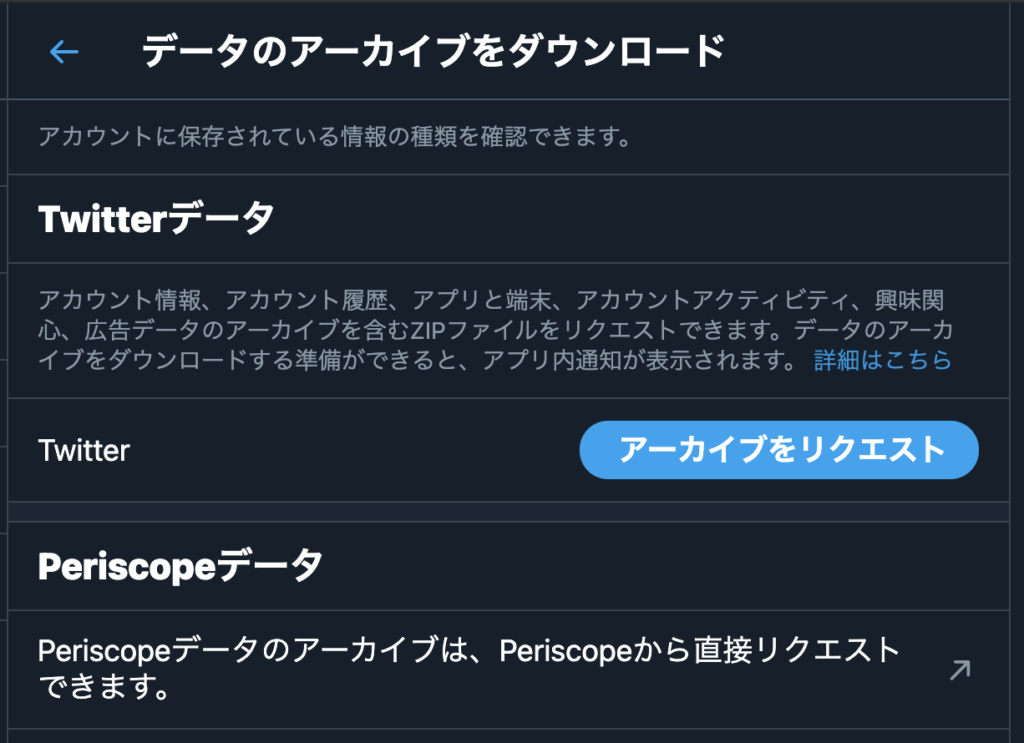
リクエスト後は、およそ1日くらいで完了通知がくるので、
リクエストしたページからファイルをダウンロードする。
アーカイブの中身
ダウンロードしたアーカイブの中身は以下のようになっている。

今回の解析対象のDMデータはdataフォルダの中にある。
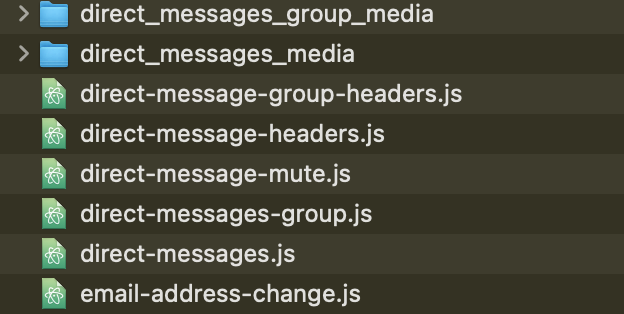
jsファイルになっているが、中身はjsonで書かれている。
direct-message.js 個別DM
direct-message-group.js グループDM
で、個人、グループでファイルがわかれている。
direct-message-group.js
今回は、グループDMの内容を解析する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
window.YTD.direct_messages_group.part0 = [ { "dmConversation" : { "conversationId" : "XXXXXXXXXX", "messages" : [ { "messageCreate" : { "reactions" : [ ], "urls" : [ ], "text" : "たしかに", "mediaUrls" : [ ], "senderId" : "XXXXXXXXXX", "id" : "XXXXXXXXXX", "createdAt" : "2021-06-12T13:16:23.075Z" } }, { "messageCreate" : { "reactions" : [ ], "urls" : [ ], "text" : "どうでもいいけどチーム名決めたくない???", "mediaUrls" : [ ], "senderId" : "XXXXXXXXXX", "id" : "XXXXXXXXXX", "createdAt" : "2021-06-12T13:16:06.893Z" } }, { "messageCreate" : { "reactions" : [ ], "urls" : [ ], "text" : "二次までは曲固定で総合点なので3人全員でAPできるならあとは時間勝負かな", "mediaUrls" : [ ], "senderId" : "XXXXXXXXXX", "id" : "XXXXXXXXXX", "createdAt" : "2021-06-12T13:15:17.080Z" } } ] } } ] |
jsonの構成は以下のようになっている。
- dmConversation
グループDM単位のルート - messages[]
グループでのメッセージ単位の配列 - text
メッセージ本文
今回のtextを解析対象とする。
(ID情報はマスクしてある。)
クラスタリングまでの流れ
- direct-message-group.jsを開く
- mecabで形態素解析をして、単語ごとにスペースで区切ったものを、textごとに配列にする
- 2でできたものをtfidfを重みとしてベクトル化する
- あらかじめ決めたクラスタ数でk-meansでクラスタリングする
- プロットするために、データのベクトル情報を二次元に圧縮する
- クラスタごとに上位5位までの重みの単語を可視化する
以上の流れに沿って、Pythonで実装する。
1.direct-message-group.jsを開く
|
1 2 3 4 |
import json f = open('/twitter_data/data/direct-messages-group.js','r') jsn_dict = json.load(f) |
direct-message-group.jsを開いて、jsonファイルとして読み込む。
2.mecabで形態素解析をする
mecabは、オープンソースの形態素解析用のエンジンで、辞書にはIPADICを用いた。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#messagesの配列抽出 jsn_messages_arr = jsn_dict['dmConversation']['messages'] #メッセージ単位に、単語をスペースで区切ったもの sentences = [] mecab = MeCab.Tagger('-Ochasen') for index, message in enumerate(jsn_messages_arr): sentence = message['messageCreate']['text'] node = mecab.parseToNode(sentence) tmp = '' while node: word = node.surface if(word != ""): tmp = tmp + word + ' ' node = node.next sentences.append(tmp) |
先述したように、DMへの投稿はmessages配列にすべて入っているのでを抽出し、
さらにその中からtextを1投稿ずつ形態素解析する。
parseToNode()メソッドにより、node.surfaceで形態素解析された単語を取得できる。
node.nextで、sentenceに格納されていてる文章の終わりまでループする。
解析された文章は、単語をスペースで区切り最終的には下記のようになる。
|
1 2 |
ノメルズ 美味い よ トイレ 行っ たら 行き ます |
3.tfidfを重みとしてベクトル化する
fit_transformメソッドを用いて、文書をtf-idf行列に変換する。
|
1 2 3 4 |
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(use_idf=True, token_pattern=u'(?u)\\b\\w+\\b') vecs = vectorizer.fit_transform(sentences) |
4.k-meansでクラスタリングする
3.での特徴量をもとにk-meansでクラスタリングを行う。
k-meansの場合、クラスタ数をあらかじめ設定する必要がある。
今回はクラスタ数を30に設定して、クラスタリングを行った。
|
1 2 3 4 |
from sklearn.cluster import KMeans NUM_CLUSTER = 30 km_model = KMeans(n_clusters=NUM_CLUSTER, random_state=0).fit(vecs) |
5.データのベクトル情報を二次元に圧縮する
クラスタリングした情報を可視化するために、
データのベクトル情報を二次元に圧縮する。
|
1 2 3 4 5 |
#次元圧縮(特異値分解)クラス初期化 lsa = TruncatedSVD(2) #サンプルデータ、およびクラスタ中心点のベクトル情報を二次元に圧縮 compressed_text_list = lsa.fit_transform(vecs) compressed_center_list = lsa.fit_transform(km_model.cluster_centers_) |
6.クラスタごとに上位5位までの重みの単語を可視化する
クラスタの中心を降順でソートしインデックス番号を取得する。
出現した単語の情報をget_feature_names()で取得する。
|
1 2 |
order_centroids = km_model.cluster_centers_.argsort()[:, ::-1] terms = vectorizer.get_feature_names() |
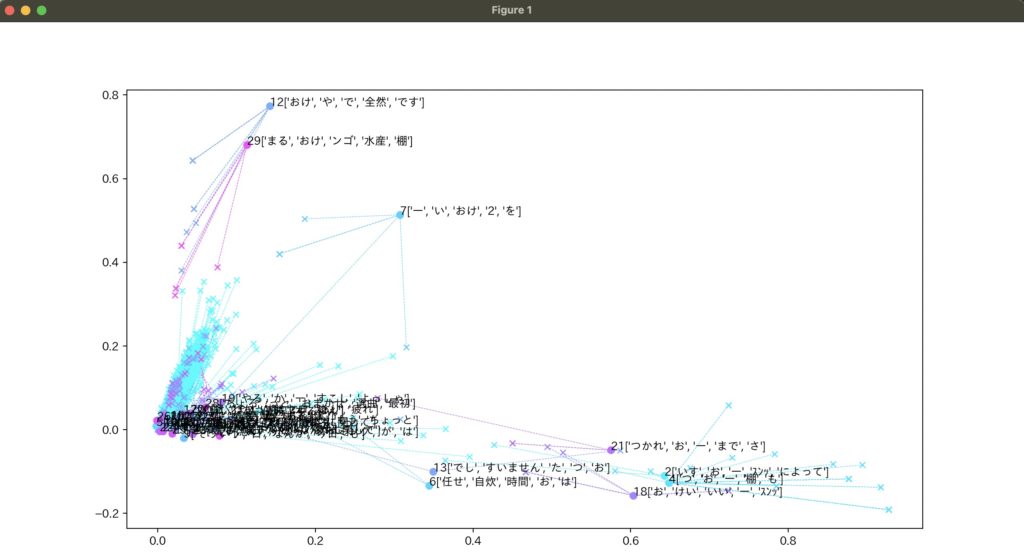
可視化した情報は下記のようになる。
(左下にクラスタが密集しすぎて見にくくなってしまった。。)
参考
Pythonで機械学習はじめました クラスタリング&次元圧縮&可視化編
MeCabを使って、テキスト中に含まれる品詞をカウントしてみよう!
Pythonでテキストをクラスタリング
コメント